敏感词匹配算法记录
记录做敏感词匹配算法的过程。


记录做敏感匹配算法的过程。
介绍
敏感词屏蔽是很多内容网站都需要做的事情,而根据公安提供的敏感词列表,具体格式如下:
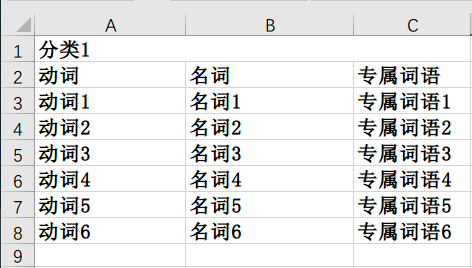
从上图可以看出,敏感词分为三类:动词、名词、专属词语,三种敏感词匹配的方式也有些不同。
专属词语是只要出现就需要屏蔽,例如:今天中午我不知道吃什么了。如果中午是一个专属敏感词的话,那么这段话中的中午就需要被屏蔽掉了。
动词和名词是需要组合才能进行匹配的,并且同一分类下的动名词都可以进行组合,如前面的图中就能组合出:动词1名词1、动词1名词2、动词2名词1、动词2名词2....,匹配的方式则是组合起来之后和专属敏感词一致,而组合之后的敏感词个数则是:动词个数V * 名词个数N(V * N)。
说到这里,可能很快就会得出一个解决方法。
#1
由于动名词最后的匹配方式是将动词和名词组合起来再进行匹配的,那么我们可以将所以分类的动名词组合起来,然后放入缓存中,这样就能大大节省在匹配敏感词的过程中进行重复组合动名词的开销。而根据公安提供的词库,最终得到的敏感词个数为:40k+,其中专属词:5.3k,动名词组合:40k,那么此时的敏感词列表格式如下:
['专属词1','专属词2','专属词3'....,'动名词组合1','动名词组合2','动名词组合3'....]
匹配算法如下:
public List<string> MatchingSensitive(List<string> senlist, string txt)
{
var returnlist = new List<string>();
foreach(var item in senlist)
{
if(txt.IndexOf(item))
{
returnlist.Add(item);
}
}
return returnlist;
}
以上这种方式虽然很简单的就能匹配出铭感词,但是性能极差,即使我们已经将所有的动名词组合放入缓存中,省去了一部分的计算开销,但是敏感词的数组大小却依然是40k+的大小,也就意味着每次都需要循环40k+次才能校验完成。并且以上代码使用了IndexOf默认方法,性能远不如Contains,具体原因可以去看看IndexOf和Contains的源码,所以我们需要把上面的代码改为:
public List<string> MatchingSensitive(List<string> senlist, string txt)
{
var returnlist = new List<string>();
foreach(var item in senlist)
{
if(txt.Contains(item))
{
returnlist.Add(item);
}
}
return returnlist;
}
现在这种方式虽然在性能上有提升,但是时间复杂度依然没有降低。我们再回过来仔细看这张图
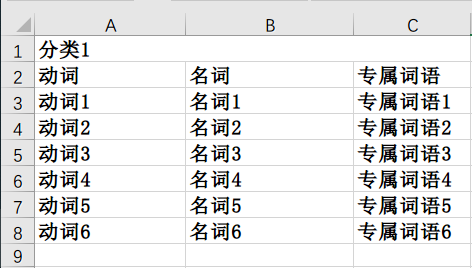
我们将所有的动名词进行组合的时候,即是对所有的敏感词进行了全量的匹配,但是真的需要这么做吗?如果将匹配的拆分为原来的动名词的话,匹配的过程如下图:
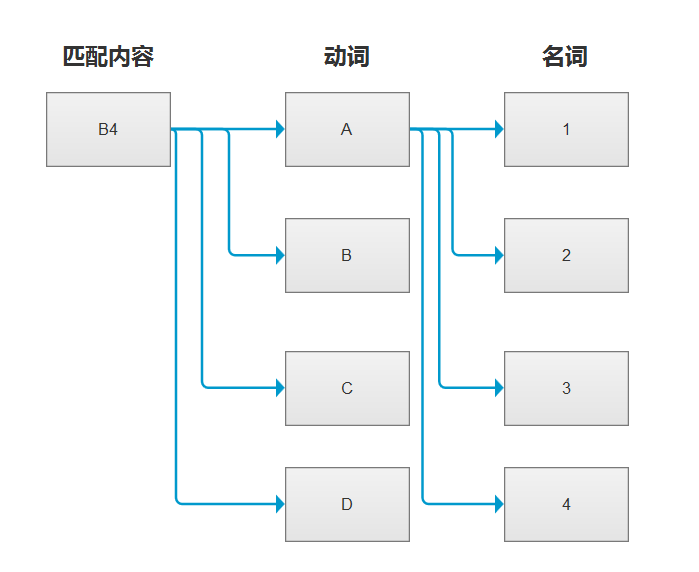
按照我们之前的全量匹配,B4会和A1、A2、A3、A4...D4都进行匹配,但是在拆分动名词的情况下,B4没有包含A,视乎根本没有必要再和A1进行匹配,因为A包含于A1、A2、A3...,若B4不包含A,即B4也不包含A1、A2、A3...,同理B4若不包含C,也就不会包含C1、C2、C3...。那么这样的话,匹配过程如下图:
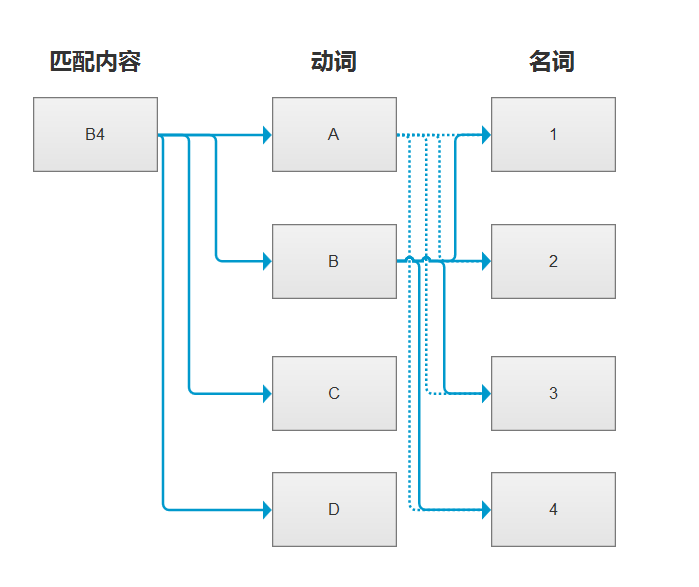
#2
根据上面的结论,如果匹配内容不包含动词,那么就无需匹配当前动词和名词组合的敏感词,所以缓存的铭感词列表数据结构需要更改为如下:
[
{
"CategoryName":"分类1",
"SensitiveList":["专属敏感词1","专属敏感词2"...],
"VerbList":
[
{
"Word":"动词1",
"CombList":["动词1名词1","动词1名词2","动词1名词3"...]
},
{
"Word":"动词2",
"CombList":["动词2名词1","动词2名词2","动词2名词3"...]
}
]
},
{
"CategoryName":"分类2",
"SensitiveList":["专属敏感词1","专属敏感词2"...],
"VerbList":
[
{
"Word":"动词1",
"CombList":["动词1名词1","动词1名词2","动词1名词3"...]
},
{
"Word":"动词2",
"CombList":["动词2名词1","动词2名词2","动词2名词3"...]
}
]
}
]
CategoryName 分类名称
SensitiveList 专属敏感词
VerbList 动词列表
CombList 动名词组合列表
代码如下
public class SenEntity
{
public string CategoryName { get; set; }
public List<string> SensitiveList { get; set; }
public List<SenVerbEntity> VerbList { get; set; }
}
public class SenVerbEntity
{
public string Word { get; set; }
public List<string> CombList { get; set; }
}
public List<string> MatchingSensitive(List<SenEntity> list, string txt)
{
List<string> senlist = new List<string>();
foreach(var sen in list)
{
//专属敏感词匹配
foreach (var senstr in sen.SensitiveList)
{
if (txt.Contains(senstr))
{
senlist.Add(senstr);
}
}
//动词匹配
foreach (var verb in sen.VerbList)
{
// 如果匹配的内容中包含了动词
if (txt.Contains(verb.Word))
{
//进行下一步的动名词组合匹配
for (int i = 0; i < verb.CombList.Count; i++)
{
var combstr = verb.CombList[i];
//如果匹配存在动名组合词
if (txt.Contains(combstr))
{
//添加动词
senlist.Add(verb.Word);
//添加名词
senlist.Add(combstr.Replace(verb.Word,""));
}
}
}
}
}
return senlist;
}
这样一来,遍历的数组长度将大大减少,时间复杂度也得到了降低,但是这就是最好的办法了吗?
我们来看一下现在匹配过程:
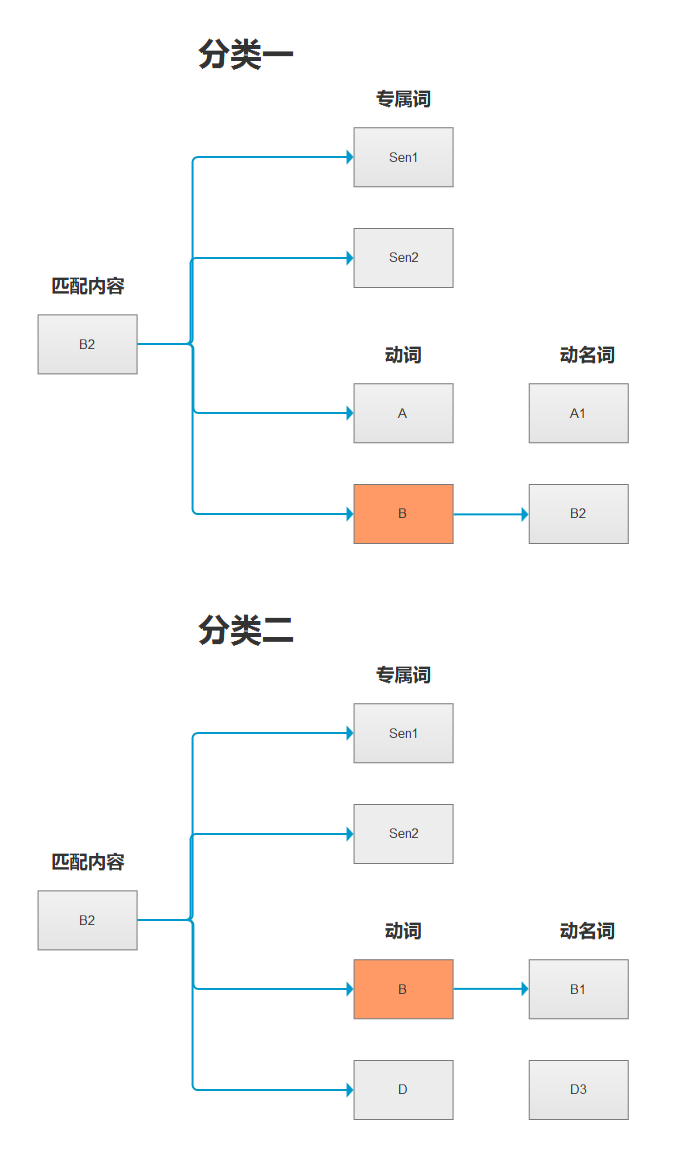
当前的数据结构由于对敏感词进行了分类,所以在匹配的时候最多会出现三层循环,并且其中不同的分类中间可能存在着相同的动词,这些数据的结构是冗余的。
#3
为了保证敏感词只匹配一次,并减少循环的复杂度。我们可以将数据结构改为如下:
专属敏感词,字典存储,key为专属敏感词
{
"专属敏感词1" : "",
"专属敏感词1" : "",
....
}
动词和动名词组合,字典存储,key为动词
{
"动词1" : ["动词1名词1","动词1名词2",,"动词1名词2"...],
"动词1" : ["动词1名词1","动词1名词2",,"动词1名词2"...],
}
原本的数组结构都改为了字典,使用字典可以保证专属敏感词或者动词不会因为在不同的分类中出现重复,这样可以简化数据的结构,并且使用两个字典来存储专属敏感词和动名词,将可以将匹配的循环缩小到两层,降低匹配过程中的时间复杂度。
匹配的代码如下:
public List<string> MatchingSensitive(Dictionary<string,string> sensitiveDic,
Dictionary<string,List<string>> verbDic, string txt)
{
List<string> senlist = new List<string>();
//专属敏感词匹配
foreach(var sen in sensitiveDic.Keys())
{
if (txt.Contains(sen))
{
senlist.Add(sen);
}
}
//动词匹配
foreach (var verb in verbDic.Keys())
{
// 如果匹配的内容中包含了动词
if (txt.Contains(verb))
{
var combList = verbDic[verb];
foreach(var comb in combList)
{
//动名词组合匹配
if (txt.Contains(comb))
{
senlist.Add(comb);
}
}
}
}
return senlist;
}
匹配的过程如下图:

以上就是对敏感词匹配过程的理解,启发于降低时间复杂度这一词,如有更好的方法,欢迎在下面留言。